Что такое data science? руководство для начинающих
Содержание:
- Как лучше хранить данные, если вы дата-сайентист
- Специализация Дата-сайентист
- Кто такой Data Scientist и чем он занимается?
- Профессия Data Scientist от Skillbox
- Как дела обстоят у нас
- Образование в области Data Science: ничего невозможного нет
- Часть 5. Датый «Data» рыцарь или еще немного о Data Science
- Большие данные
- Что мне нравится в моей работе
- Дата-сайентисты в облаках
- Data Scientist – в чём нужно разбираться
- Часть 2. Batman Data Science: Начало
Как лучше хранить данные, если вы дата-сайентист
Обычно Аркадий работает с небольшими датасетами и хранит их в файлах от 50 до 100 Мб. Но с новым проектом к нему пришел большой набор данных, и Аркадий решил как обычно сложить его в csv-файл, который получился объемом 13 Гб. И здесь начинаются проблемы.
Такой файл сложно передать кому-то из коллег: вы будете очень долго ждать, пока он загрузится в Slack или Google Drive. А еще он может вообще не открыться на компьютере. Или формат такого файла плохо доходит до прода: объем данных растет с каждым днем и файл разрастается.
Что же можно с этим сделать? Посмотрим, как хранят файлы разработчики.
-
Они используют базы данных, оптимизированные под свои задачи и под тот объем данных, который у них есть.
-
Валидируют форматы данных при загрузке.
-
Поддерживают отказоустойчивость сервисов и баз данных, которые к ним подключены.
-
Заранее думают о возможностях масштабирования. То есть сразу прогнозируют, насколько объем данных вырастет через год, и нужно ли будет переделывать архитектуру с нуля, или у них будет возможность масштабироваться до нужного объема.
Конечно, дата-сайентистам не всегда нужно делать отказоустойчивые сервисы, но тем не менее, они могут подсмотреть некоторые штуки, которые облегчат работу.
Мы уже поняли, что сохранять все в csv-формате — не вариант. Такой файл не влезет в RAM среднестатистического компьютера, а скорость чтения явно превысит 2 минуты. В этом случае нет никакой оптимизации, валидации форматов, отказоустойчивости и масштабируемости.

Попробуем разделить этот файл по отдельным партициям. Например, найти колонку с маленькой вариативностью данных, по которой можно разделить их и сложить в отдельные файлы. После этого мы сможем обрабатывать отдельные файлы под необходимые задачи. Так мы решаем проблему масштабируемости, но размер файлов все равно остается большим.
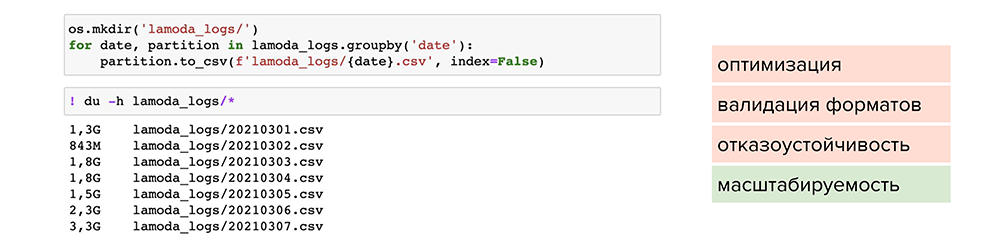
Теперь попробуем сжать файлы. Например, можно воспользоваться обычной утилитой сжатия для одного файла gzip. Она доступна в pandas, нужно лишь при сохранении указать ее в параметре , и файл станет весить 1,2 Гб вместо 13 Гб. Но читается он также 2 минуты. Делаем вывод, что такой способ мало подходит для оптимизации, хотя масштабируемость присутствует — файлы стали занимать меньше места на диске.
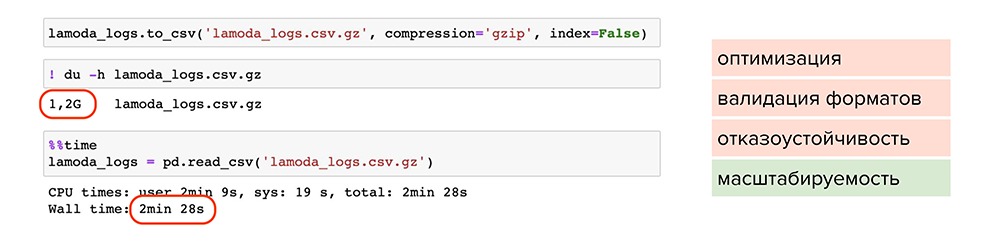
Попробуем улучшить результат. Например, можно использовать parquet — это специальный формат сжатия или, более умными словами, партиционированная бинарная колоночная сериализация для табличных данных. Он позволит работать с каждым типом данных в каждой колонке отдельно: например, сжимать числовые данные одним способом, текстовые или строковые данные — другим способом, и таким образом оптимизировать как хранение информации, так и чтение.
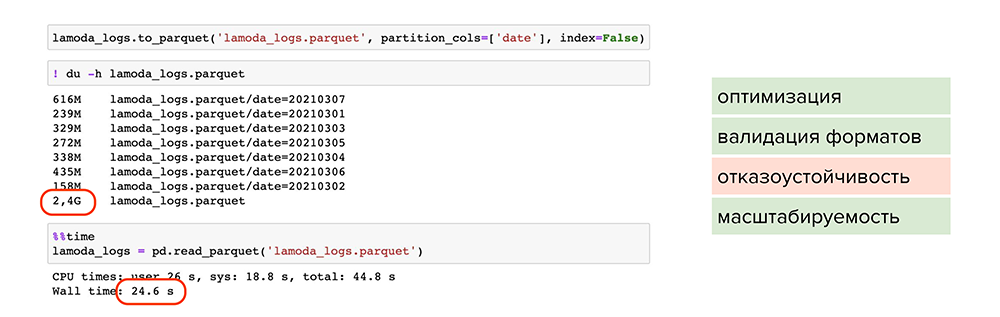
С применением parquet:
-
Большой объем данных стал весить 2,4 Гб и читаться за 24 секунды. Файлы оптимально сжаты, поделены на партиции и у каждого есть метаданные.
-
Происходит валидация форматов, поскольку parquet работает с каждым форматом колонки отдельно и проверяет их при записи. Вероятность записать ошибочные данные снижается.
-
Присутствует масштабируемость, поскольку мы пишем данные в разные партиции и сжимаем их.
Однако мы не победили один пункт — отказоустойчивость.
Чтобы покрыть все пункты, можно обратиться к специальным фреймворкам и базам данных. Например, подойдут ClickHouse или Hadoop, особенно, если это продакшн-решения или повторяющиеся истории.
Специализация Дата-сайентист
Полный функционал Data scientist зависит от направления деятельности предприятия, на котором специалист трудится.
Основные должностные обязанности:
- сбор сведений из разных каналов для дальнейшего анализа;
- прогнозирование моделей базы клиентов, ее сегментация для продвижения конкретных продуктов;
- изучение эффективности продаж;
- анализ всевозможных рисков;
- составление периодичных и разовых отчетов с визуализацией полученных результатов и прогнозирование показателей на перспективу;
- обнаружение мошеннических схем по сомнительным операциям.
Хороший специалист этой отрасли отличается от новичка умением выявлять логические цепочки в общем массиве информации, предлагая руководству оптимальные бизнес-решения.
Кто такой Data Scientist и чем он занимается?
Говоря простыми словами, это специалист по анализу данных. Он собирает их, объединяет в базы, ищет и анализирует закономерности и на этой основе создает модели, которые помогают принимать те или иные решения. Чаще всего они востребованы в следующих сферах: ИТ, телеком, банки и финансы, консалтинг, маркетинг, научные исследования.
Какие задачи они решают:
- Создание рекомендательных систем.
- Формирование прогнозов, например, на рынках акций.
- Создание скоринговых систем, которые принимают решения на основе анализа большого объема данных. Например, выдать кредит клиенту или нет.
- Выявление аномалий в различных системах. Например, для автоматической блокировки подозрительных банковских операций.
-
Персонализированный маркетинг. Формирование уникальных предложений для клиентов, акций, скидок.
Чтобы проще понять, чем занимается Data Scientist, разберем пример рекомендательного алгоритма. Многие музыкальные сервисы на основе статистики прослушиваний могут предлагать пользователям другие треки, которые им понравятся. Алгоритм, по которому работает эта программа, создает специалист по анализу больших данных.
Все больше компаний собирают различные базы данных, которые используются для разных целей. Поэтому востребованность специалистов растет. Им предлагают хорошие зарплаты, о чем расскажем ниже.
Мы разобрались, кто такой Data Scientist и что это за профессия. Пора поговорить о преимуществах и недостатках данной работы.
Профессия Data Scientist от Skillbox
Для анализа больших и неоднородных массивов данных используется технология Big Data. Машинные технологии научились делать выводы и использовать инфографику для визуализации данных. На услуги Data Scientist предъявляют спрос банки, мобильные операторы, производители программных продуктов. Уровень оплаты в Big Data стабильно высок. Обучиться профессии с нуля могут новички, а опытные программисты прокачают свои навыки. Курс от Skillbox задействует разные инструменты — языки кода, фреймворки, библиотеки и базы данных.
Освоение новых знаний происходит в контакте с наставником. Сообщество профессионалов Skillbox даёт обратную связь при выполнении заданий и помогает выпускникам с трудоустройством.
Как дела обстоят у нас
Мы создаем систему городской мобильности с человеческим отношением к пассажирам и водителям. И хотим сделать это отраслевым стандартом. Хотим встречать и провожать пассажиров в аэропорты и на вокзалы; доставлять важные документы по указанным адресам быстрее курьеров; сделать так, чтобы на такси было не страшно отправить ребёнка в школу или девушку домой после свидания, даем возможность выбрать транспорт — каршеринг, такси или самокат. И даже если нашим пассажиром является котик, то ему должно быть максимально комфортно.
У нас есть большой отдел эффективности платформы (или Marketplace), где в каждом из направлений работают специалисты по обработке и анализу данных.
-
Ценообразование: правильный и правдоподобный предрасчет цены для клиента на предстоящую поездку. Мы разрабатываем алгоритмы, которые тонко настраивают наши цены под специфические региональные и временные условия, а также помогают нам держать вектор оптимального ценового роста и развития
-
Клиентские мотивации: помогают нам привлекать новых клиентов, удерживать старых и делать нашу цену самой привлекательной на рынке. Основное направление — это разработка алгоритма оптимального распределения бюджета на скидки клиентам для достижения максимального количества поездок. Мы стремимся создать выгодное предложение для каждого клиента, поддержать и ускорить наш рост
-
Водительские мотивации: одна из главных задач Ситимобил — забота о водителях. Наши алгоритмы создают для них среду, в которой каждый работает эффективно и зарабатывает много. Мы стремимся разработать подход, позволяющий стимулировать водителей к выполнению поездок там, где другие алгоритмы не справляются: возмещаем простой на линии, если нет заказов, и гарантируем стабильность завтрашнего дня для привлечения всё новых и новых водителей.
-
Динамическое ценообразование: главная задача направления — гарантировать возможность уехать на такси в любое время и в любом месте. Достигается это за счет кратковременного изменения цен, когда желающих уехать больше, чем водителей в определенной гео-зоне.
-
Распределение заказов: эффективные алгоритмы назначения водителей на заказ уменьшают длительность ожидания и повышают заработок водителей. Задача этого направления — создать масштабируемые механизмы назначения, превосходно работающие как в целом по городам, так и в разрезе каждого тарифа.
-
Исследование эффективности маркетплейсов: центральное аналитическое направление, задачей которого является анализ эффективного баланса между количеством водителей на линии и пассажирами.
-
ГЕО сервисы: эффективное использование геоданных помогает различным командам эффективно настраивать свои алгоритмы, которые напрямую зависят от качества этих данных. Мы стремимся создавать такие модели, сервисы и алгоритмы, которые не только повышают качество маршрутизации и гео-поиска, но и напрямую воздействуют на бизнес, а также клиентский опыт.
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.
Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Часть 5. Датый «Data» рыцарь или еще немного о Data Science
Поскольку первая учебная программа была пройдена за день, а особых знаний не прибавилось, логично было продвинуться дальше, тем более сами разработчики учебных программ советуют перейти к Data Science for Business, ну и еще я решил посмотреть в сторону курса Statistics 101, с него и начну.
Statistics 101 – Похоже к этому курсу ребята «сдулись», потому, что после определенного момента к видео не сделали субтитры, конечно есть автоматический перевод Youtube, но по мне это не очень удобно. С моим плохим английским курс кажется сложным, по крайней мере если вам раньше в ВУЗе не давалась статистика, сложно ожидать, что вот на «басурманском» языке к вам придет озарение. И тем не менее курс несложный и что-то полезное сообщает (средне квадратичное отклонение, медиана, дисперсия и т.д.). Может быть есть смысл посмотреть его перед курсами по Data Science, а может и нет, вам решать.
Важно отметить, что для этого курса надо регистрироваться качать триал версию программы SPSS Statistics. Триал всего 14 дней, так что хоть формально время курса и не ограничено, лучше совсем не затягивать
Программа сама по себе дорогая, а курс завязан во многом на нее, поэтому в конечном счете курс мне не понравился =)
Data Science for Business
Состоит из:
- Data Privacy Fundamentals
- Digital Analytics & Regression
- Predictive Modeling Fundamentals
К первым двум курсам нет субтитров для видео (вроде).
Кратко про каждый:
Data Privacy Fundamentals – курс на примере канадского законодательства говорит о том, как важно соблюдать информационную безопасность. Кроме текста и видео в курсе будет одно упражнение, где нам с помощью заготовок на R, подскажут как легко взломать ненадежные пароли
Ну а на экзамене придется «хакнуть» пароль для бедолаги Джастина (можно не «хакать», а просто «включить голову»)
Digital Analytics & Regression – курс наконец-то дает хоть немножечко адекватной практики и демонстрации анализа «небольших» данных на R. Не абы что, но все же полезно.
Predictive Modeling Fundamentals I – ужасный курс, на видео мужик часто шипит в микрофон и говорит так как будто у него во рту … леденец, причем не знаю глюк или нет, но на youtube видео не выложено, а в плеере на сайте нельзя включить субтитры так, чтобы они вылезали как нормальные субтитры (получается только сбоку) в итоге просмотр видео превращается в пытку.
Курс заточен под еще одно творенье от IBM — SPSS Modeler, так что надо опять скачивать триал (в этот раз на 30 дней)
В отличии от прошлых курсов материал к лабораторным нормально не подготовлен и если где-то ошибся, то решение надо искать самому, сверится не с чем, контрольного файла нет.
В рамках курса разбирают задачку про Титаник (как я понял тема, избитая до жути)
Я его до конца не осилил, после второго модуля сдался, просто бегло просмотрел видео, в трудных местах залез в Википедию, ответил на тесты + экзамен и успешно сдал этот курс (что еще раз говорит о низкой ценности сертификатов).
Большие данные
Начнём с простого — big data, или «большие данные». Это модный термин, обозначающий огромные массивы данных, которые накапливаются в каких-то больших системах.
Например, человек в Москве совершает 5-6 покупок по карте в день, это около 2 тысяч покупок в год. В стране таких людей, допустим, 80 миллионов. За год это 160 миллиардов покупок. Данные об этих покупках — биг дата.
В банках какой-то страны каждый день совершаются сотни тысяч операций: платежи, переводы, возвраты и так далее. Данные о них хранятся в центральном банке страны — это биг дата.
Ещё биг дата: данные о звонках и смс у мобильного оператора; данные о пассажиропотоке на общественном транспорте; связи между людьми в соцсетях, их лайки и предпочтения; посещённые сайты; данные о покупках в конкретном магазине (которые хранятся в их кассе); данные с шагомеров и тайм-трекеров; скачанные приложения; открытые вами файлы и программы… Короче, любой большой массив данных.
Почему появился такой термин: в конце девяностых компании в США стали понимать, что сидят на довольно больших массивах данных, с которыми непонятно что делать. И чем дальше — тем этих данных больше.
Раньше данные были, условно говоря, по кредитным картам, телефонным счетам и из профильных государственных ведомств; а теперь чем дальше — тем больше всего считается. Супермаркеты научились вести сверхточный учёт склада и продаж. Полиция научилась с высокой точностью следить за машинами на дороге. Появились смартфоны, и вообще вся человеческая жизнь стала оцифровываться.
И вот — данные вроде есть, а что с ними делать? Тут на сцену выходит дата-сайенс — дисциплина о больших данных.
Минутка занудства. Все знают, что правильно говорить «биг дэйта», потому что именно так произносят носители языка. Но в русском языке этот термин прижился с побуквенной транслитерацией — как написано, так и читаем. Поэтому — дата. Кстати, с сайентистами такого не произошло — они звучат так же, как в оригинале.
Что мне нравится в моей работе
Я работаю в «Тинькофф» уже три с половиной года. В нашей компании много задач для сайентистов и почти нет ограничений по развитию. Наука о данных — достаточно универсальная область
По сути тебе не важно какими данными ты занимаешься: о торговле продуктами или о поведении пользователей в интернете. Для всех задач есть одинаковая база: математика и программирование
Зная базовые вещи уже можно углубляться в конкретные области, например, компьютерное зрение или обработку естественного языка.
Большинство задач в индустрии довольно стандартные, они ориентированы прежде всего на бизнес-результат. Поэтому в какой-то момент каждому специалисту хочется начать делать что-то свое параллельно основной работе. Я, например, хотел бы привнести что-то новое в open-source (программы и технологии для разработчиков), но пока своих значимых кейсов нет.
Мне нравится создавать технологии, которые автоматизируют ручную работу. Например, известная в машинном обучении библиотека scikit-learn поделила профессию на «до» и «после»: у разработчиков появились инструменты для быстрой работы с алгоритмами ML.
Еще мне хотелось бы углубиться в другие области машинного обучения. Я занимаюсь временными рядами, обычно в этой специализации лучше работают классические модели. И хочу поглубже копнуть в Deep Learning — глубинное обучение, где нейросети способны решать очень сложные задачи. Именно в этой области сейчас происходят наиболее интересные в машинном обучении вещи.
Курс
Полный курс по Data Science
Освойте востребованную профессию с нуля за 12 месяцев и станьте уверенным junior-специалистом.
- Индивидуальная поддержка менторов
- 10 проектов в портфолио
- Помощь в трудоустройстве
Получить скидку Промокод “BLOG10” +5% скидки
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Data Scientist – в чём нужно разбираться
Требования к подготовке и уровню профессиональных навыков зависят от того, в какой компании предстоит работать специалисту
Например, в крупных корпорациях аналитику данных важно разбираться в математике и статистике. Маркетплейсам и медиакомпаниям нужны эксперты в разработке рекомендательных систем, а в крупном ритейле — в разработке машинного зрения
Такие навыки востребованы на HeadHunter. Цифра означает количество вакансий
Преподаватели школы SkillBox изучили вакансии в области Data Science на российском и зарубежном рынке и составили список навыков и областей знаний, которые понадобятся успешному специалисту:
- Программирование.
- Анализ.
- Математика и статистика.
- Машинное обучение и глубокое обучение.
- Data Engeneering.
- Data Science в продакшн.
Часть 2. Batman Data Science: Начало
На сайте после регистрации открывается доступ к множеству курсов. Все курсы, что мне попадались можно было начинать в любой момент, ограничений по времени не было, взаимодействие с преподавателями или студентами тоже не требовалось.
Каждый курс можно пройти по отдельности, а можно в составе учебной программы (learning path). За прохождение каждого учебного курса выдается электронный сертификат, за выполнение требований учебной программы — бейдж
Интерфейс сайта напоминает любую другую систему дистанционного обучения, так что думаю сам процесс не должен вызывать проблем у опытных пользователей.
Поскольку о Data Science на момент регистрации я не знал вообще ничего, сам бог велел начать с программы обучения Data Science Fundamentals, в принципе это же мне подтвердил местный «Скайнет». На сайте есть бот (Student Advisor), если ему написать: «Data Science», то он как раз присоветует эту учебную программу. Для каких-либо более сложных и душевных бесед бот не подходит, потому что он понимает похоже только ключевые слова из тем курсов.
Приступим. На странице учебной программы, видно, что она состоит из нескольких курсов, ранжированных в рекомендуемом порядке прохождения (хотя никто не запрещает проходить в любом порядке).
При этом, для получения бейджика первой степени, как правило необходимо освоить самый первый курс учебной программы, для получения бейджика второй степени необходимо, как правило пройти все курсы программы. Рассмотрим её подробней.